- 1. 网络层的归一化方式
- 2. 如何理解Batch?
- 3. 评估指标
- 4. NMS
- 5. Loss
- 6. BN
- 7. ROI pooling vs ROI Align
- 8. 模型压缩与加速
- 9. 跟踪算法
- 9.4. 光流算法
- 9.5. MeanShift
- 9.6. Kalman
- 深度学习基础:点击查看内容
网络层的归一化方式
setup: 特征图谱的维度是 (B, C, H, W)
BN(批归一化)
对整个特征图谱的通道层计算μ和σ:一共得到C个(μ,σ)
layer normalization(层归一化)
对每个样本的特征图谱计算(μ,σ):一共得到B个(μ,σ)
适用于RNN
instance normalization(实例归一化)
对每个样本的每一个通道计算(μ,σ):一共得到(B, C)个(μ,σ)
适用于“风格迁移”场景
group normalization(组归一化)
介于层归一化和实例归一化之间:每一个样本单独计算(μ,σ),但是却是将C个通道分成S个组,每个组单独计算(μ,σ)。一共得到S个(μ,σ)。
如何理解Batch?
为什么不一个样本一个样本的方式输入,而要一次输入say 64个样本?硬件更加强大,1个样本与64个样本所用时间相差不大;遍历一次数据集的速度也更快;每一次更新的梯度综合多个样本,抑制某些样本带来的波动,收敛速度更快。
评估指标
指标基础
| 预测 \ 实际 | 1[实际,阳性样本] | 0[实际,阴性样本] |
|---|---|---|
| 1[预测] | TP | FP |
| 0[预测] | FN | TN |
基础:TP、FP、FN、TN
第二个字母表示预测结果:P,阳性;N,阴性
第一个T、F表示预测结果是否正确:T,正确;F,错误
TP:正确预测为阳性之样本
FP:错误预测为阳性之样本
精度(precision) = 预测为正的样本中确实为正的比率
TPR(true positive rate):所有阳性样本被正确判断为阳性的比例
FPR(false positive rate):所有阴性样本中,错误地判断为阳性之比例
ROC
以 TPR为纵轴,FPR为横轴,绘制一条曲线即为ROC(receiver operating characteristic),越靠近左上角越好。
【1. 如何绘制ROC?2.】
AUC
由于ROC曲线并不能清晰地表明哪一个分类模型较好,因此采用AUC进行评估。ROC曲线下面积即为AUC值。
PR曲线 (precision-recall)
precision:精度
recall:召回率
以精度为纵轴,召回率为横轴,所得到的曲线。曲线靠近右上方。曲线从(0, 1) 一直到(1, 0)

距离应该满足三个特性
- 非负 $dist(x, y) >= 0$
- 对称 $dist(x, y) = dist(y, x)$
- 三角不等式 $dist(x, y) <= dist(x, z) + dist(z, y)$
余弦距离满足严格距离的定义吗?
- dist
NMS
1 | 把概率太低的box剔除掉 |
1 | # code implementation |
soft-NMS:用于可以部分用于解决两个物体重叠度较高的问题。不像NMS对重叠度超过阈值的直接删除,而是降低其概率
两种方式降低概率
- 高斯加权
- 线性加权
手写IoU
1 | def iou(box1, box2): |
Loss
- 手写交叉熵
二值交叉熵
bce形式
sigmoid函数
函数导数为 σ(1-σ)
binary cross entropy loss 对 inputs x的导数为 预测值 与 实际值的 差
Softmax公式
softmax用于把logits转为probs,最终再采用cross_entropy计算损失L.
结论: L对logits_i 的梯度 : (预测值与实际值的差)pi - yi, pi是计算出的i类概率, yi是第i个输出的真实标签。
softmax函数对输入的梯度:输出j对输入$i$的梯度。
Focal Loss
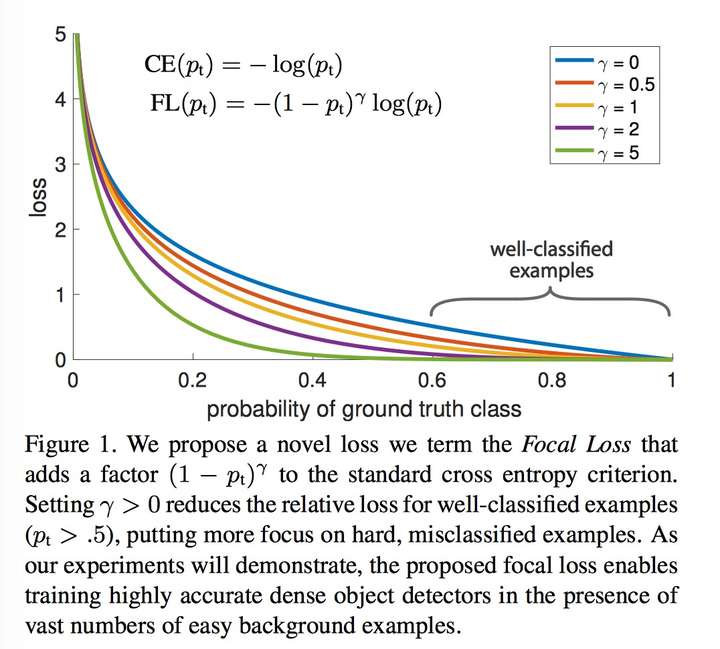
focal loss的公式
回顾softmax cross-entropy的公式,我们可以看到只有真实类别的一项有损失贡献。focal loss降低了置信度较高的输出的loss
同时为了调整不同类别的权重予不同类别以不同的权重
调节正负样本均衡的传统手段α
α是权重系数, α是针对类别y=+1, 1−α是针对类别y=−1的。
调节难易样本(1−pt)γ
其中γ大于0, 常取值为2。样本简单时,1−pt小;样本难时,
1−pt大。
1 | import numpy as np |
卷积参数量计算
BN
- 以(相对)大学习率学习,加速收敛速度
- 能提高精度
- 相当于正则化(类似于Dropout):使用BN时,每个样本都会和其他样本一起输入(彼此互相影响),网络对一个样本的输出也就不是确定的
ROI pooling vs ROI Align
roi pooling: 预测的框是离散,需要取整一次(从原图上面的框到feature map上面的框);接下来pooling的时候又会45 -> 2 2又会取整一次(5/2 向上、向下取整) misalignment的问题,语义分割 像素问题
roi align: 直接将feature map划分为 输出大小 H*w, 每个框里再选择4个点(作者发现4个点效果要好一些),插值取得这每个hw里面的四个点的值,再做pooling. 解决roi pooling中的量化不匹配问题。
模型压缩与加速
模型压损(尺寸变现)与加速(运算速度变快)
某些算法用内存换时间,winograd conv2d(卷积操作变矩阵相乘,再将矩阵相乘变为)
算法层
量化与剪枝、网络结构优化、模型蒸馏
网络结构优化(矩阵分解、分组卷积、小卷积核等)
- 矩阵分解
- 分组卷积
- 使用类似于深度可分卷积,紧接一个1x1的卷积
- 分解卷积
- 用两个3x3卷积串联替换5x5卷积
- 用1xn和nx1的卷积并联替换
nxn卷积
- 其他
- 全局池化替换全连接
- 1x1卷积的使用
- 小卷积替代大卷积
量化(quantization)与定点化(Fixed-Point)
模型量化是指权重或激活输出可以被聚类到一些离散、低精度(Reduced precision)的数值点上,通常依赖于特定算法库或硬件平台的支持
训练后量化
训练时量化,forward采用低精度,但是bp-gradient的时候是高精度
伪量化
常见的做法是保存模型每一层时,利用低精度来保存每一个网络参数,同时保存拉伸比例scale和零值对应的浮点数zero_point。推理阶段,利用如下公式来网络参数还原为32bit浮点
伪量化之所以得名,是因为存储时使用了低精度进行量化,但推理时会还原为正常高精度。为什么推理时不仍然使用低精度呢?这是因为一方面框架层有些算子只支持浮点运算,需要专门实现算子定点化才行。另一方面,高精度推理准确率相对高一些。伪量化可以实现模型压缩,但对模型加速没有多大效果。
聚类与伪量化
一种实现伪量化的方案是,利用k-means等聚类算法,步骤如下:
将大小相近的参数聚在一起,分为一类。
每一类计算参数的平均值,作为它们量化后对应的值。
每一类参数存储时,只存储它们的聚类索引。索引和真实值(也就是类内平均值)保存在另外一张表(codetable,代码表)中
推理时,利用索引和映射表,恢复为真实值。定点化 Fixed-Point
定点化在推理时,不需要还原为浮点数。这需要框架实现算子的定点化运算支持。目前MNN、XNN等移动端AI框架中,均加入了定点化支持。
模型剪枝
- 剪枝流程
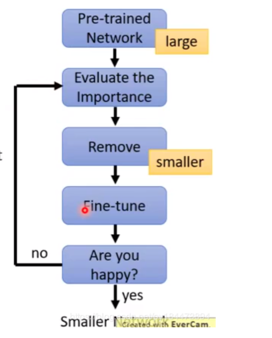
- 训练一个performance较好的大模型。
- 评估模型中参数的重要性。常用的评估方法是,越接近0的参数越不重要(或者用gradient大小)。当然还有其他一些评估方法,这一块也是目前剪枝研究的热点。
- 将不重要的参数去掉,或者说是设置为0。之后可以通过稀疏矩阵进行存储。比如只存储非零元素的index和value。
- 训练集上微调,从而使得由于去掉了部分参数导致的performance下降能够尽量调整回来。
- 验证模型大小和performance是否达到了预期,如果没有,则继续迭代进行。
突触简枝 突触剪枝剪掉神经元之间的不重要的连接。对应到权重矩阵中,相当于将某个参数设置为0。常见的做法是,按照数值大小对参数进行排序,将大小排名最后的k%置零即可,k%为压缩率。
神经元剪枝 神经元剪枝则直接将某个节点直接去掉。对应到权重矩阵中,相当于某一行和某一列置零。常见做法是,计算神经元对应的一行和一列参数的平方和的根,对神经元进行重要性排序,将大小排名最后的k%置零。
权重矩阵剪枝 除了将权重矩阵中某些零散的参数,或者整行整列去掉外,我们能否将整个权重矩阵去掉呢?答案是肯定的
有很多paper围绕“怎么判断权重是否重要”以及“如何剪枝”等问题进行讨论。困扰模型剪枝落地的一个问题就是剪枝比例的确定。传统的剪枝方法常常需要人工layer by layer地去确定每层的剪枝比例,然后进行fine tune,用起来很耗时,而且很不方便。
不过最近的Rethinking the Value of Network Pruning指出,剪枝后的权重并不重要,对于channel pruning来说,更重要的是找到剪枝后的网络结构,具体来说就是每层留下的channel数量。受这个发现启发,文章提出可以用一个PruningNet,对于给定的剪枝网络,自动生成weight,无需进行retrain,然后评测剪枝网络在验证集上的性能,从而选出最优的网络结构。
模型蒸馏
蒸馏流程
蒸馏本质是student对teacher的拟合,从teacher中汲取养分,学到知识,不仅仅可以用到模型压缩和加速中。
训练学生网络去模仿老师网络的输出,以老师网络的输出作为label进行网络优化(老师输出:softlabel;真实标签 hard-label)。soft-loss可以采用KL散度或者均方误差。
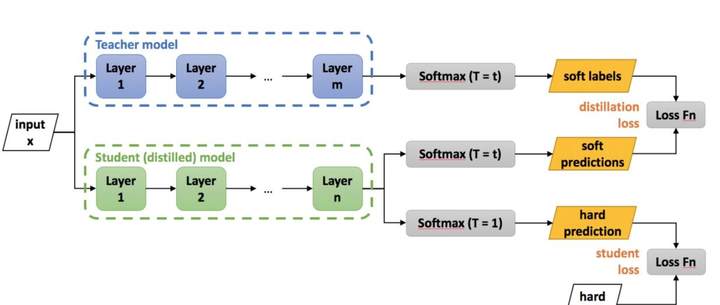
框架层
目前移动端AI框架也比较多,包括谷歌的tf-lite,腾讯的NCNN,阿里的MNN,百度的PaddleLite, 小米的MACE等。他们都不同程度的进行了模型压缩和加速的支持。特别是端上推理的加速。
端侧AI框架加速优化方法
缓存优化
- 小块内存反复使用,提升cache命中率,尽量减少内存申请。比如上一层计算完后,接着用作下一层计算。
- 连续访问,内存连续访问有利于一次同时取数,相近位置cache命中概率更高。比如纵向访问数组时,可以考虑转置后变为横向访问。
多线程。
- 为循环分配线程。
- 动态调度,某个子循环过慢的时候,调度一部分循环到其他线程中。
稀疏化
- 稀疏索引和存储方案,采用eigen的sparseMatrix方案。
内存复用和提前申请
- 扫描整个网络,计算每层网络内存复用的情况下,最低的内存消耗。推理刚开始的时候就提前申请好。避免推理过程中反复申请和释放内存,避免推理过程中因为内存不足而失败,复用提升内存访问效率和cache命中率。
硬件层
有点意思:
A校的文科 和理科的升学率都高于b校;但是b校整体的升学率却高于A校?
参考: 一位算法工程师从30+场秋招面试中总结出的超强面经——目标检测篇(含答案)
跟踪算法
质心追踪算法
- 检测,计算质心
- 将质心分配给last帧,欧拉距离最近的id
- 如果某个last object找不到对象,则消失,并disappear count += 1
- 如果有一个新的object匹配不到上一帧,则register 该物体
registorderegister
相关滤波算法
KCF
(怎么做?)
总结一下,KCF中用到的加速方法:
1)检测:使用循环矩阵+傅里叶变化计算响应图,原本O(n^3)的算法只需要O(nlg(n))
2)训练:利用循环矩阵性质,在频域进行训练
3)核回归提速:对于核函数,也可以转化到频域进行训练和检测,大大提高速度
4)特殊核函数进一步加速:对于高斯核,多项式核可以进一步利用循环矩阵计算核函数的循环矩阵
真是一步一步引人入胜的算法。KCF特点
1、通过循环移位产生了大量的虚拟样本;
2、利用循环矩阵可以在傅里叶域对角化的性质,大大减少了运算量,提高了运算速度;
3、核函数的运用,提高了分类器的性能;
4、采用HOG特征,相对于灰度特征和颜色特征,准确度更高;KCF steps
- 在当前对象 x 上面拟合一个filter α
- 去下一帧图像对应区域去寻找response,能匹配上的区域响应最大
- 根据下一帧寻找到的区域 x,重新训练一个filter α, 重复前两步
编程
1 | import numpy as np |
ref2: principle
光流算法
两个基本假设条件
- 亮度恒定不变:同一目标在不同帧间运动时,其亮度不会发生改变。
- 时间连续或运动是“小运动”:即时间的变化不会引起目标位置的剧烈变化,相邻帧之间位移要比较小。同样也是光流法不可或缺的假定。
ref1 csdn blog
MeanShift
1 | 有一系列点,表示的数据分布 |
mean shift向量
对于给定的d维空间Rd中的n个样本点xi,i=1,⋯,n,则对于x点,其Mean Shift向量的基本形式为:
其中,Sh指的是一个半径为h的高维球区域。里面所有点与圆心为起点形成的向量相加的结果就是Mean shift向量。
引入核函数的mean shift向量
ref2 机器学习聚类算法之Mean Shift
Kalman
卡尔曼滤波有两个作用
- 计算不能直接测量的量
- 融合多传感器的测量值
1 | # 卡尔曼滤波线性形式 |
object detection bench mark https://github.com/foolwood/benchmark_results
傅里叶变换
空间域与频率域之间的互换
参考:数字图像处理-傅里叶变换章节